Summary:
Apache Hive is a open-source project in the Hadoop ecosystem, designed to meet the requirement of query over large set of data. Hive will take a SQL-like language and compile the code into MapReduce jobs to distribute and parallelize the query. It has very similar functionality to Pig Latin overall, which is trying to build a higher layer upon messy MapReduce execution.
Strong points:
- Hive is similar to SQL with all the simple primitive types and nested data structures. So many old SQL code could be reused in Hive and gain a second life.
- Programmers don’t have to worry about the execution and storage since everything is taken care of. The file will be stored in HDFS (scalable and fault-tolerant) and the execution will be done with the compiler and Hadoop engine. The programmers can focus on the queries they are going to run instead of spending time on low-level programming.
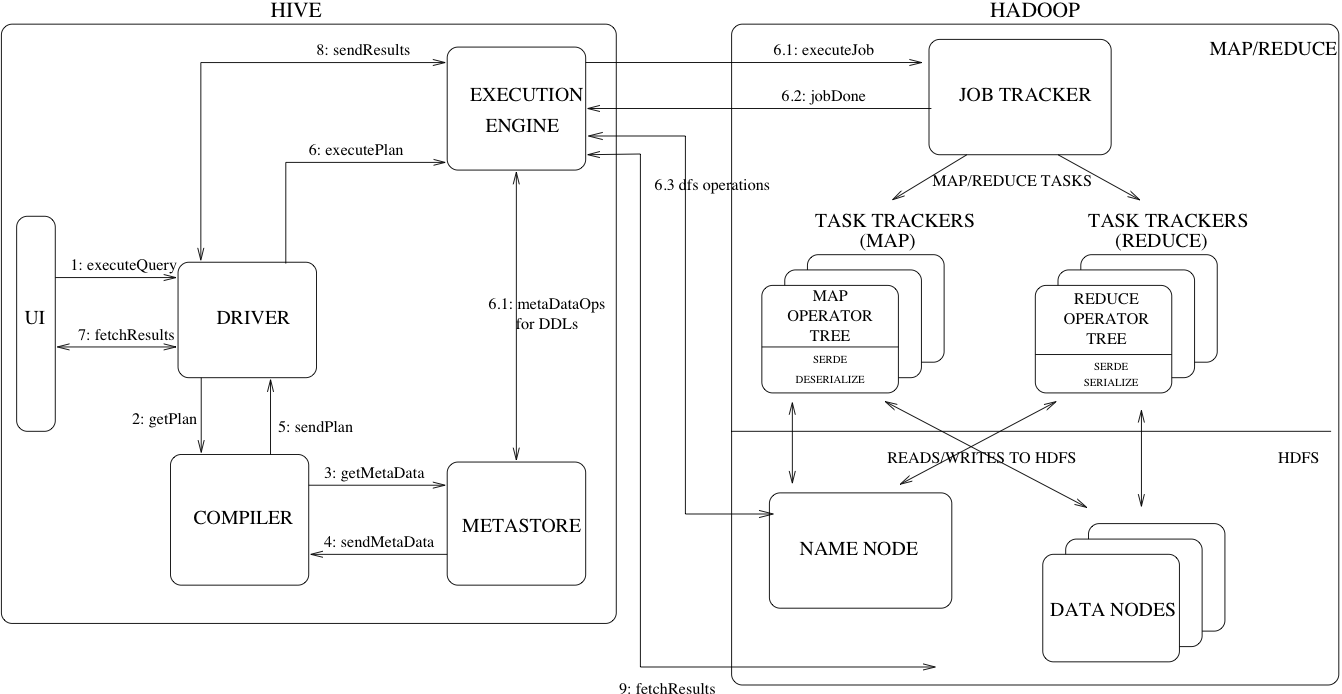
- The internal design of Hive is complex but clear. Every component has very distinctive jobs to do and decouples user interface from the coordination, compilation and execution. There is a picture of the design of Apache Hive at the end of this review, which I found very helpful. As I pointed out, the execution flow is very easy to understand.
Weak points:
- Hive was originally planned back in 2007 and got open sourced in 2008, so Hadoop MapReduce is pretty much the only choice as execution engine for Hive. It’s definitely one of the main drawbacks of Hive from today’s point of view since Hadoop is much slower than other distributed execution engine like Spark. Replacing Hadoop with Spark or something else would make Hive much faster. I’ve seen some works about Hive on Spark or Spark SQL, and the latter one is claimed to be 100 times faster than original Hive according to Is Apache Spark going to replace Hadoop.
- I personally prefer the control flow language like Pig Latin over declarative query language like HiveQL. Programmers can use control flow language to achieve and organize complex nested logic and hence better for extracting more information from data. Pig scripts are also easy to optimize and efficient comparing to SQL-like code. Even from the SQL’s standard, Hive is not complete considering that it doesn’t have update, delete or row level insert operations.
- Hive could be bad for small data set because of many reasons: MapReduce is a batch-oriented execution model and has long start overhead; Hive itself need to compile the code into executable MapReduce jobs; the distributed storage underneath (HDFS) add another layer of latency. So overall the system has lots of overhead and cannot run small queries efficiently.
Picture from Design – Apache Hive